Quick Deployment of DeepSeek R1 Distributed Inference
This platform provides a job template for quickly deploying DeepSeek R1 distributed inference. You can directly use it to create distributed tasks, quickly deploy your own DeepSeek, or launch a Web UI interface to interact with large models.
Quick Deployment of DeepSeek R1 Distributed Inference
The Job Template section provides the DeepSeek R1 Distributed Inference task template. You can directly select this template to quickly deploy DeepSeek R1 distributed inference, or launch a Web UI interface to interact with large models.
Selecting a Template to Create a Job
Click on the job template in the sidebar, and then select the DeepSeek R1 Distributed Inference template.
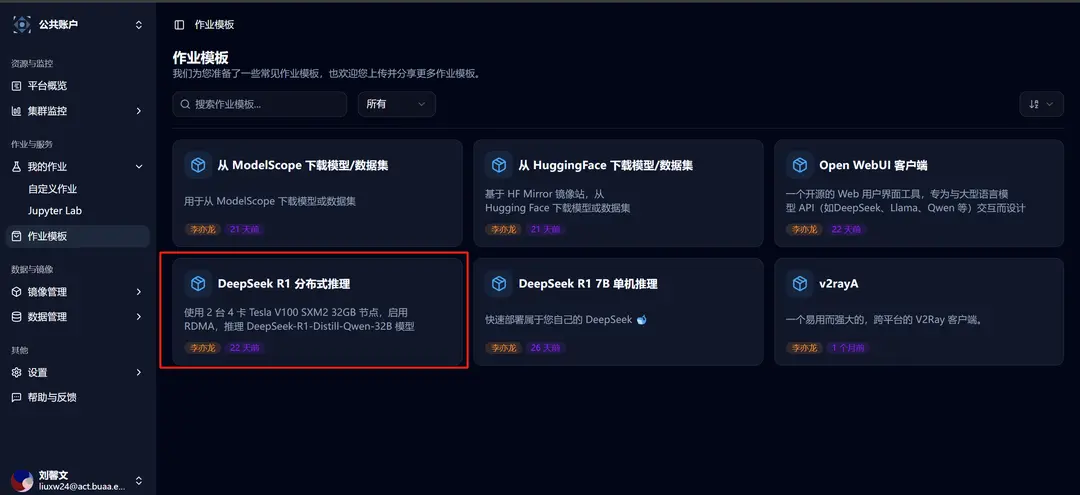
After selection, you will be redirected to the new custom job interface, where you can see that the relevant template parameters are already filled in:
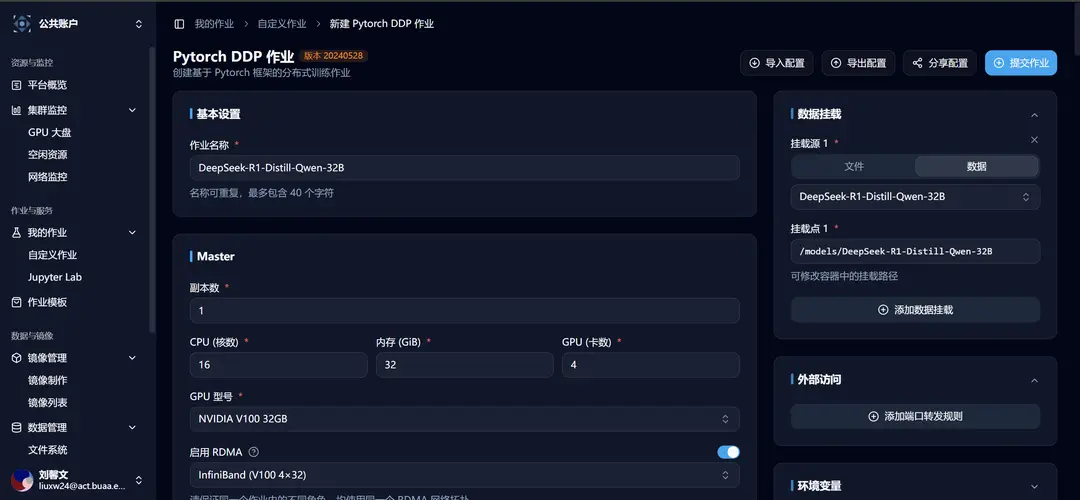
Launch Command and Common Issues
Launch Command
The launch command in the template is as follows:
ray start --head --port=6667 --disable-usage-stats;
NCCL_DEBUG=TRACE python3 -m vllm.entrypoints.openai.api_server \
--model=/models/DeepSeek-R1-Distill-Qwen-32B \
--max-model-len 32768 \
--tensor-parallel-size 4 \
--pipeline-parallel-size 2 \
--gpu-memory-utilization 0.90 \
--max-num-seqs 128 \
--trust-remote-code \
--disable-custom-all-reduce \
--port 8000 \
--dtype=half;Common Issues
Issue 1: ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla V100-SXM2-32GB GPU has compute capability 7.0. You can use float16 instead by explicitly setting the dtype flag in CLI, for example: --dtype=half.
Answer 1: Add the vLLM launch parameter --dtype=half. The main reason for this issue is that many acceleration operators cannot run on V100, which is a 无奈 choice. Many high-performance operators have certain hardware limitations.
Issue 2: How to estimate how much computing power is needed?
Answer 2: The minimum memory usage is >= number of model parameters * deployment bit width (bit) / 8. For example, if a 32b model is deployed using 16bit, the minimum required memory is 64GB. A single v100 in crater has 32GB of memory, so in practice, 3-4 v100s may be sufficient. We didn't use that many cards for testing multi-machine setups and instead used 8 cards.
Issue 3: Can we use sglang?
Answer 3: The sglang framework does not support deployment with GPUs with compute capability 7.0. Some features of vllm are also not fully supported on V100. You can check the vllm documentation and issue area for more details.
At this point, you can already interact with the DeepSeek R1 32b model deployed using the job template! 🥳!
Launch Web UI Interface and Interact with Large Models
The Open WebUI client template is used in conjunction with model deployment templates to provide a friendly experience for trying out large models.
Click on the job template in the sidebar, and then select the Open WebUI client template.
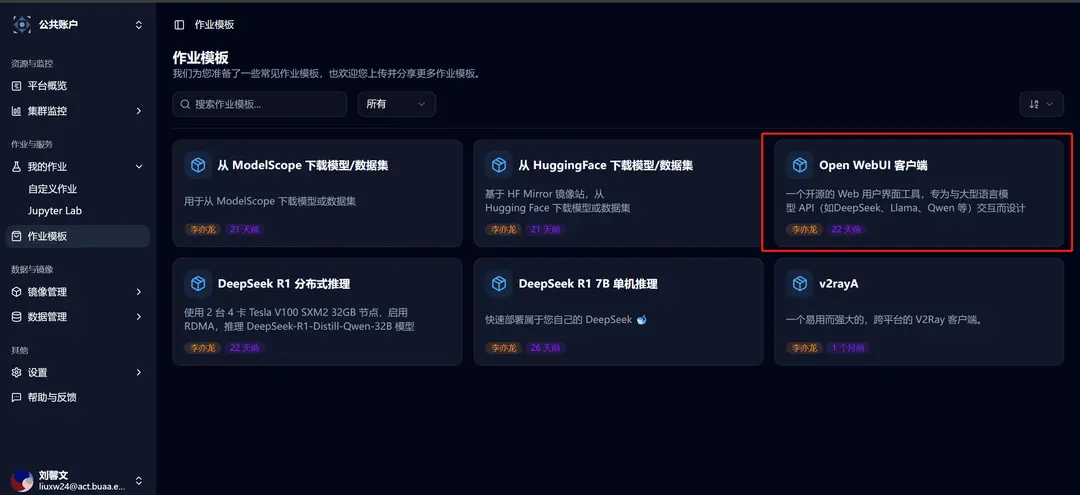
After selection, you will be redirected to the new custom job interface, where you can see that the relevant template parameters are already filled in:
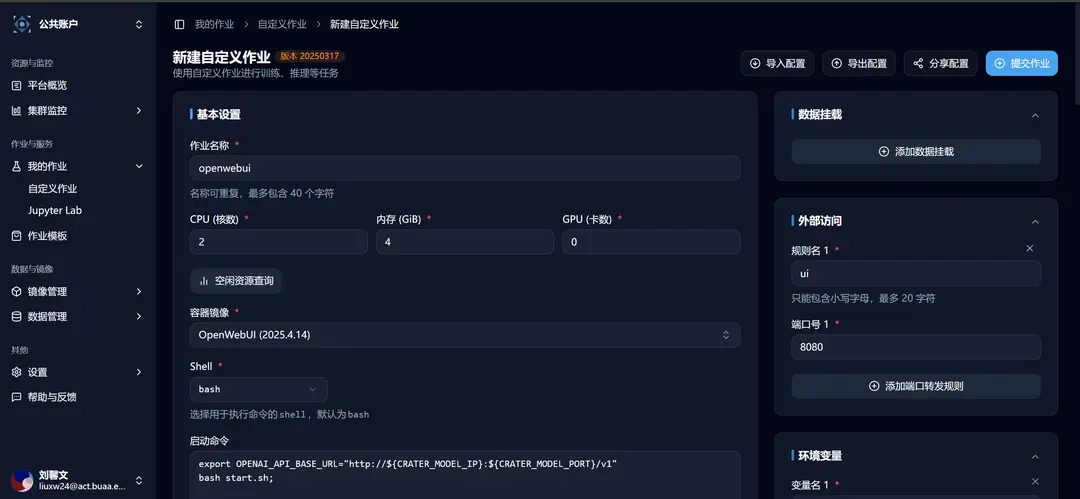
After launching the large model inference service on the Crater platform using the DeepSeek R1 distributed inference task template, you need to modify the first environmental variable, the OpenAI service address:
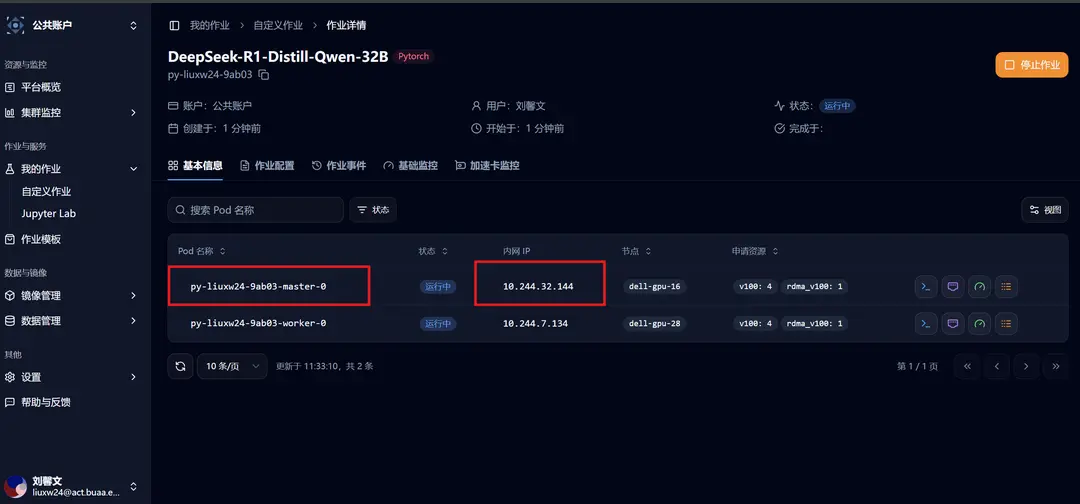
For multi-machine deployment of the model, it corresponds to the internal IP of the Ray Head node in the job's basic information:
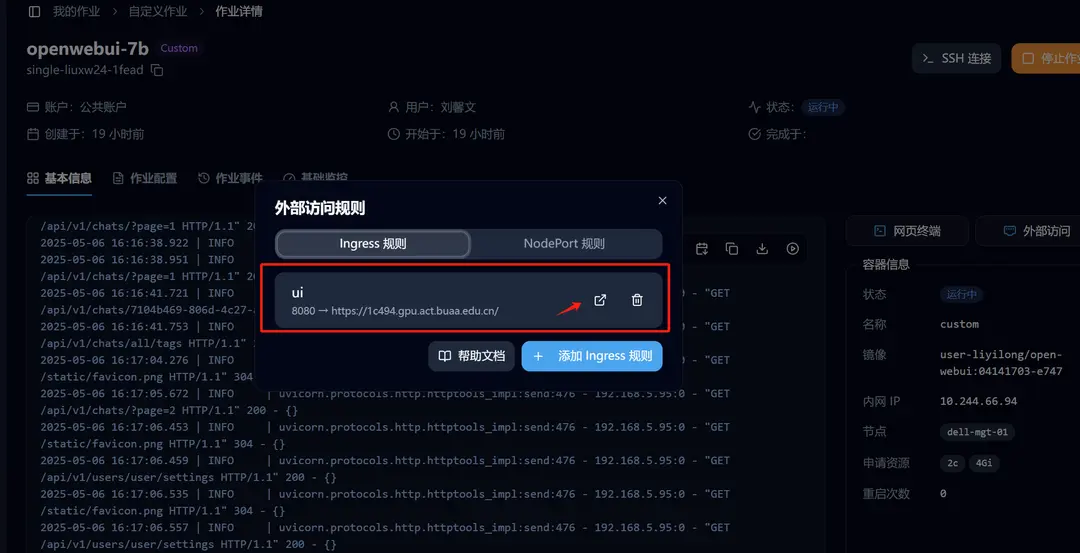
After successfully launching Open WebUI, go to the details page and click on External Access. We have already set up the forwarding, and you can click to access it.
Start your journey with large models! 🥳!
Edit on GitHubWeb Terminal
Documentation for Web Terminal
Quick Deployment of DeepSeek R1 Single-Machine Inference
This platform provides a job template for quickly deploying DeepSeek R1 single-machine inference. You can directly use it to create single-machine tasks and quickly deploy your own DeepSeek, or start the Web UI interface to interact with large models.