Custom Job
Submit a PyTorch Handwritten Digit Recognition GPU Training Job
Batch Job
Submit a PyTorch Handwritten Digit Recognition GPU Training Job
Crater's Single-Machine Batch Task is used to execute instructions in a specific environment and obtain results.
Upload Code
Create Code Locally
Create the code file to be executed locally. Considering the inconvenience of the batch system in the code debugging phase, it is recommended to only use code that has been successfully debugged and can run normally locally, applied to the batch system, to ensure the smooth progress and stability of the overall business process.
# This code is referenced from the PyTorch handwritten digit recognition GPU training task example on github
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=2, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--no-mps', action='store_true', default=False,
help='disables macOS GPU training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
use_mps = not args.no_mps and torch.backends.mps.is_available()
torch.manual_seed(args.seed)
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main()Upload Local Code
Open the file system in data management within the system and enter the user space
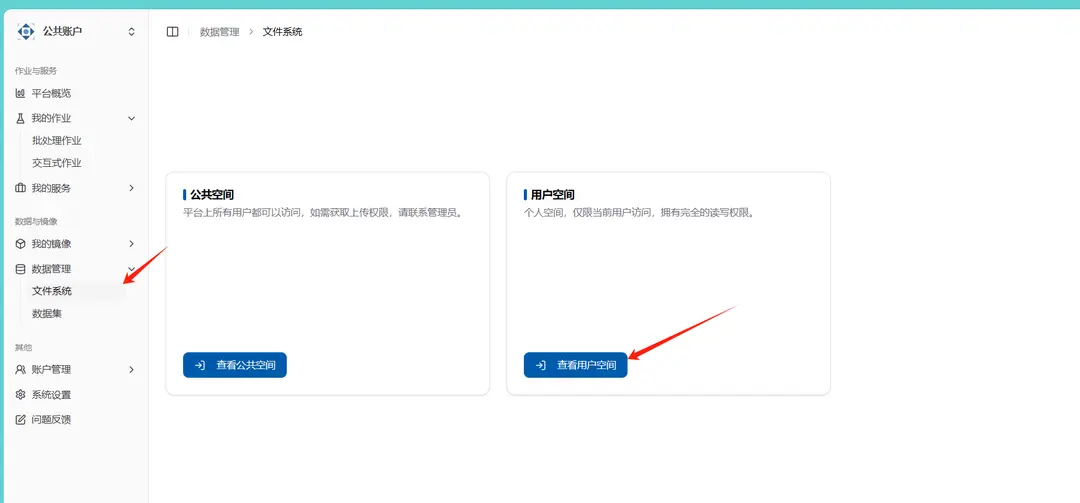
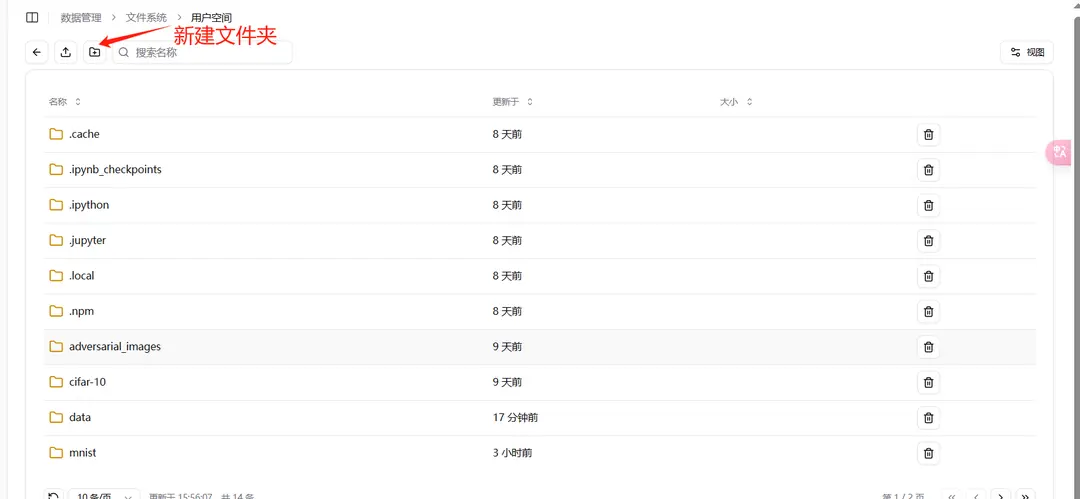
You can create a new folder specifically for the project and import the relevant files.
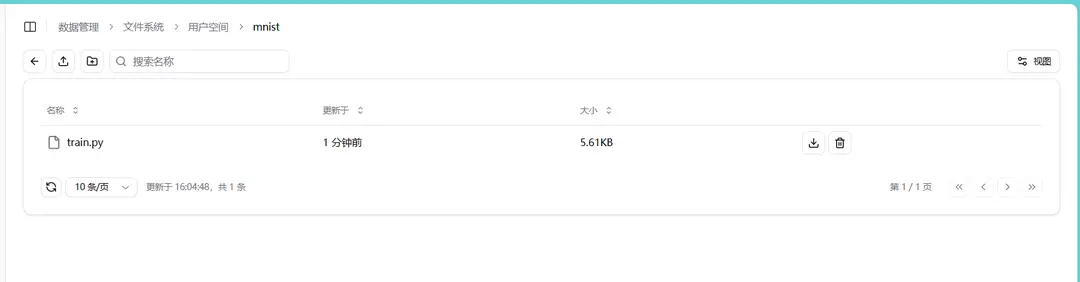
In this example, the train.py file is imported into the mnist folder.
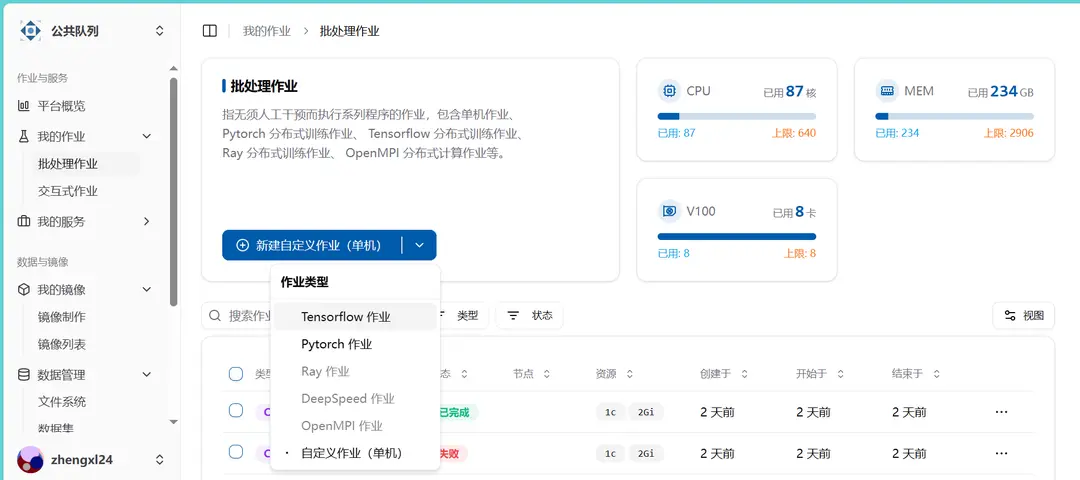
Submitting a Job
Select the custom single-machine batch job in the batch job.
Fill in Job Information
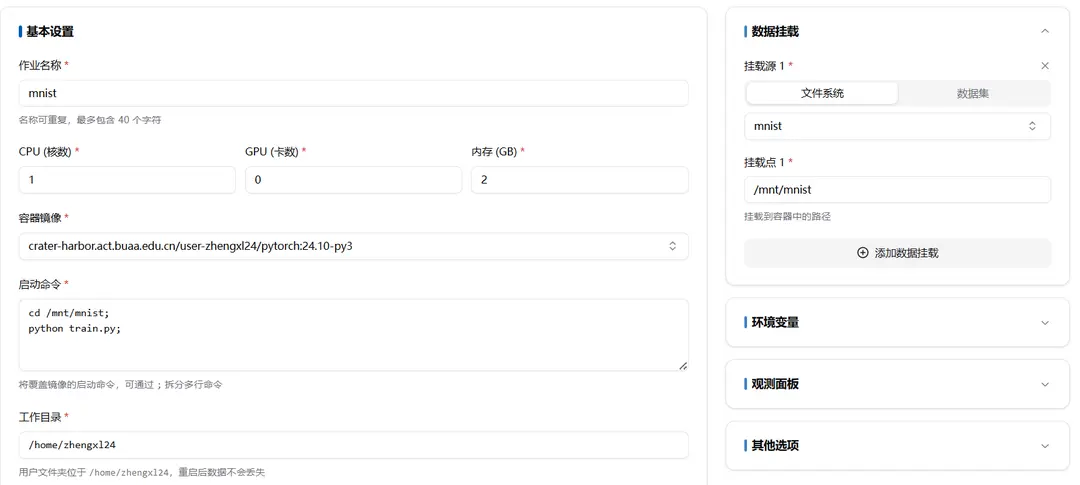
Container Image Selection
You can choose a public image or your own image. The introduction of public images and how to create your own image is described in the relevant documentation.
Startup Command
Example Command
cd /mnt/mnist;
python train.py- Open the /mnt/mnist folder
- Run train.py with Python
Notes
- Ensure that commands are separated by
;so that they are executed sequentially in the same shell session. - If the command contains special characters or spaces, it is recommended to enclose the entire command string in quotes to avoid parsing errors.
By doing this, you can override the default startup command of the image and execute multi-line commands when starting the container.
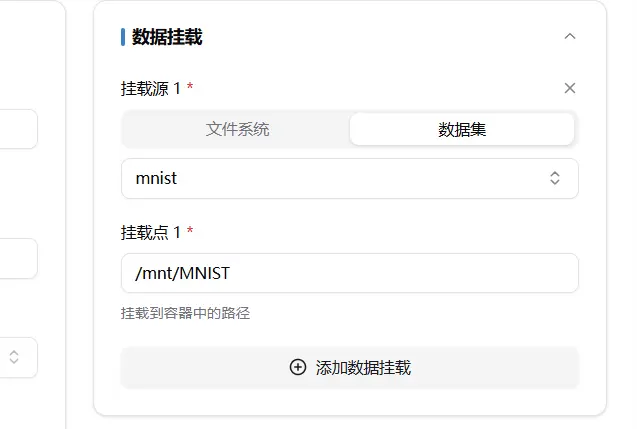
Data Mounting
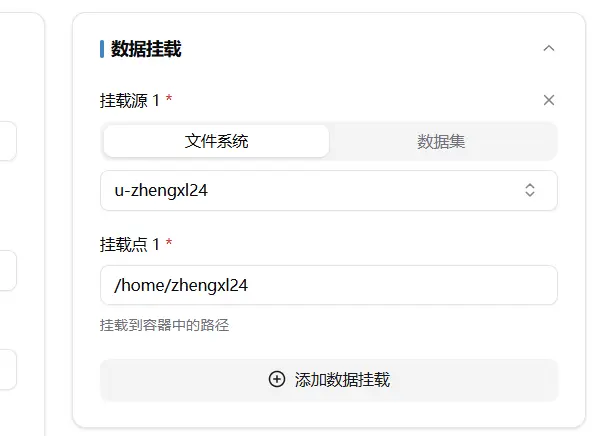
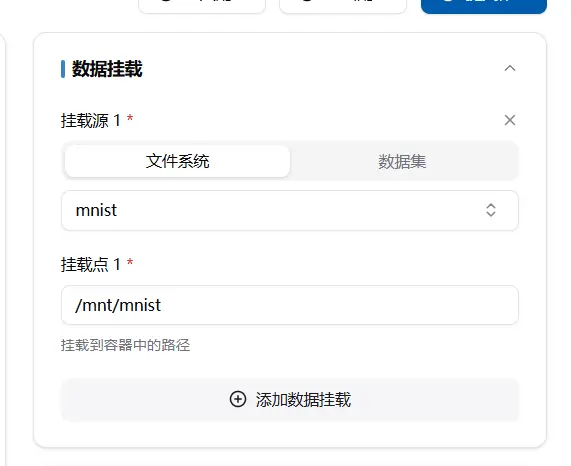
The initial state is to mount the entire user file system. Generally, the file system and dataset are mounted to the /mnt/ folder.
For example, to import the mnist folder from the user space, you can use the cd /mnt/mnist; command to access this folder.
Similarly to the folder, the dataset mounting actually mounts the entire folder containing the dataset to the /mnt/ folder, as shown below.
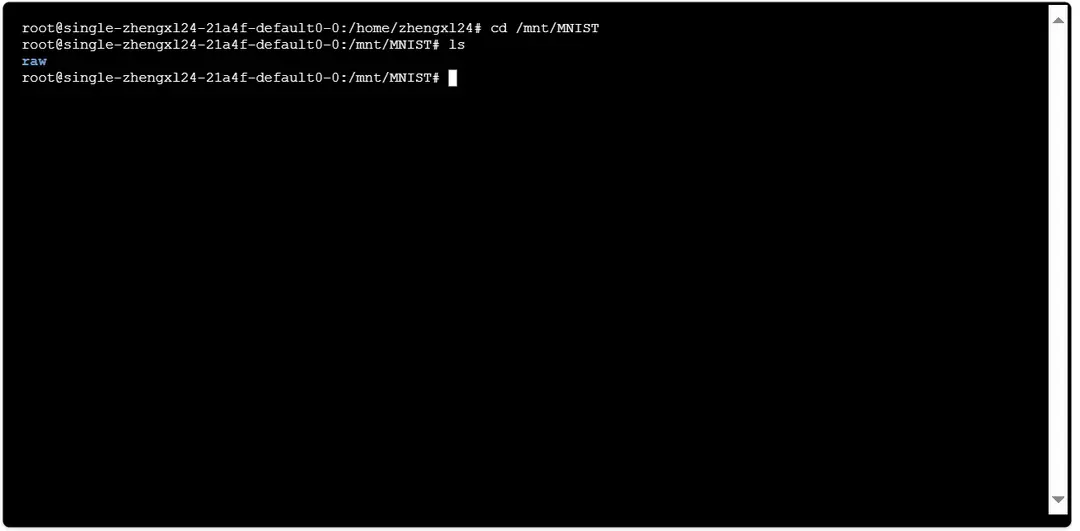
Check Job Status
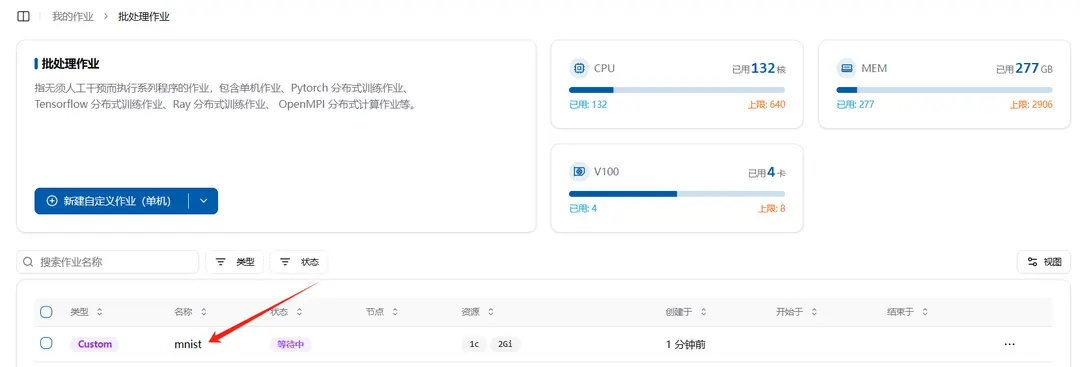
After successfully creating a job, you can see the newly created job in the batch job list. Click the job name to view details.
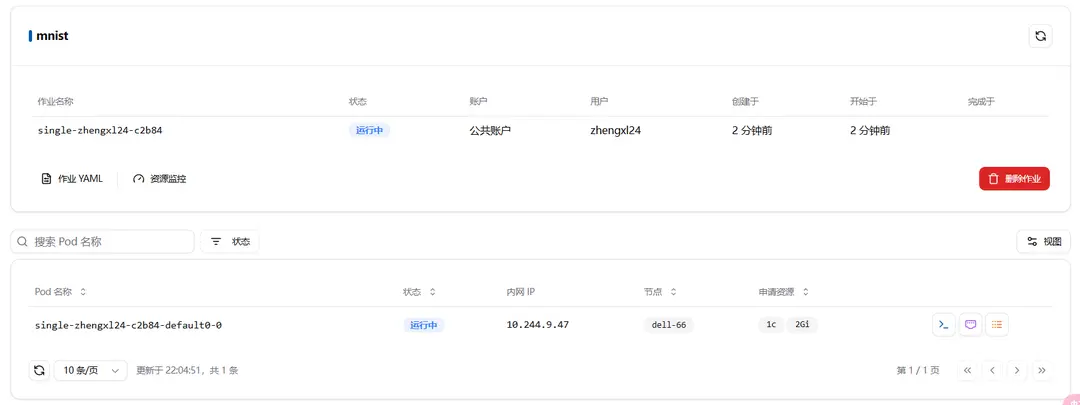
During the job execution, errors may occur, such as being unable to open the corresponding folder or issues during program execution. You can check the job status by viewing the logs.

At this point, the program is downloading the dataset. Due to the system proxy, the download speed might be slow. You can download the dataset in advance and upload it.
If the status changes to Completed, it indicates that the batch job has been executed successfully. If it fails, it means there is an issue, which you can check through the logs.

Other Ways to Check Job Status
At the same time, when creating a new batch job, you may encounter some environmental issues. You can add the sleep command in the Startup Command for debugging. For example:
sleep 600;//pause the program for 10 minutesThen, you can check the information you want through the terminal and logs.

Job Result Saving
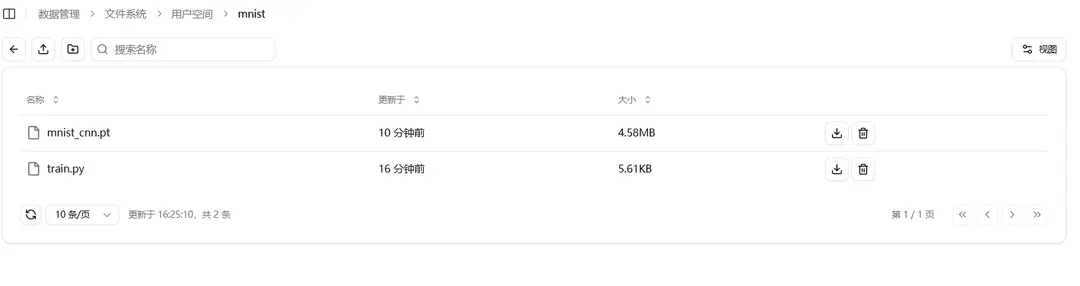
The content saved in the current folder of the image space during the execution of the file will be saved to the original folder in the user space. For example, in the sample code, after running, it will save the mnist_cnn.pt file to the original folder mnist where train.py is located.
torch.save(model.state_dict(), "mnist_cnn.pt")